L'IA qui se connecte à tout. Sécurisée en France. Du chatbot au collaborateur autonome.
Connectez l'IA à votre ERP, CRM et systèmes internes, d'un chatbot sécurisé à des collaborateurs IA entièrement autonomes. Sur serveurs français, modèles open source, 100% conforme RGPD. Plus une équipe néerlandaise qui construit et fait évoluer le tout pour vous.
Serveurs 100% français · IA open source · Conforme RGPD · Équipe néerlandaise
Ils ont déjà choisi IntraGPT
L'IA en Europe : AI Act & RGPD en pratique
Pourquoi les organisations déployant l'IA en Europe choisissent une IA locale et open-weight comme IntraGPT pour vraiment respecter l'AI Act et le RGPD.
- Classification des risques AI Act et ce que cela signifie pour vos cas d'usage
- RGPD & traitement des données : pourquoi les API Big Tech sont juridiquement problématiques
- Liste pratique pour une implémentation IA conforme
- Pourquoi l'hébergement local + open-weight est la seule voie durable
Pourquoi IntraGPT ?
En savoir plusUn LLM local avec raisonnement sur votre propre serveur privé. Complet avec chat, agents, documents, base de connaissances, sécurité certifiée ISO 27001 et une équipe néerlandaise qui vous accompagne dans la bonne utilisation.
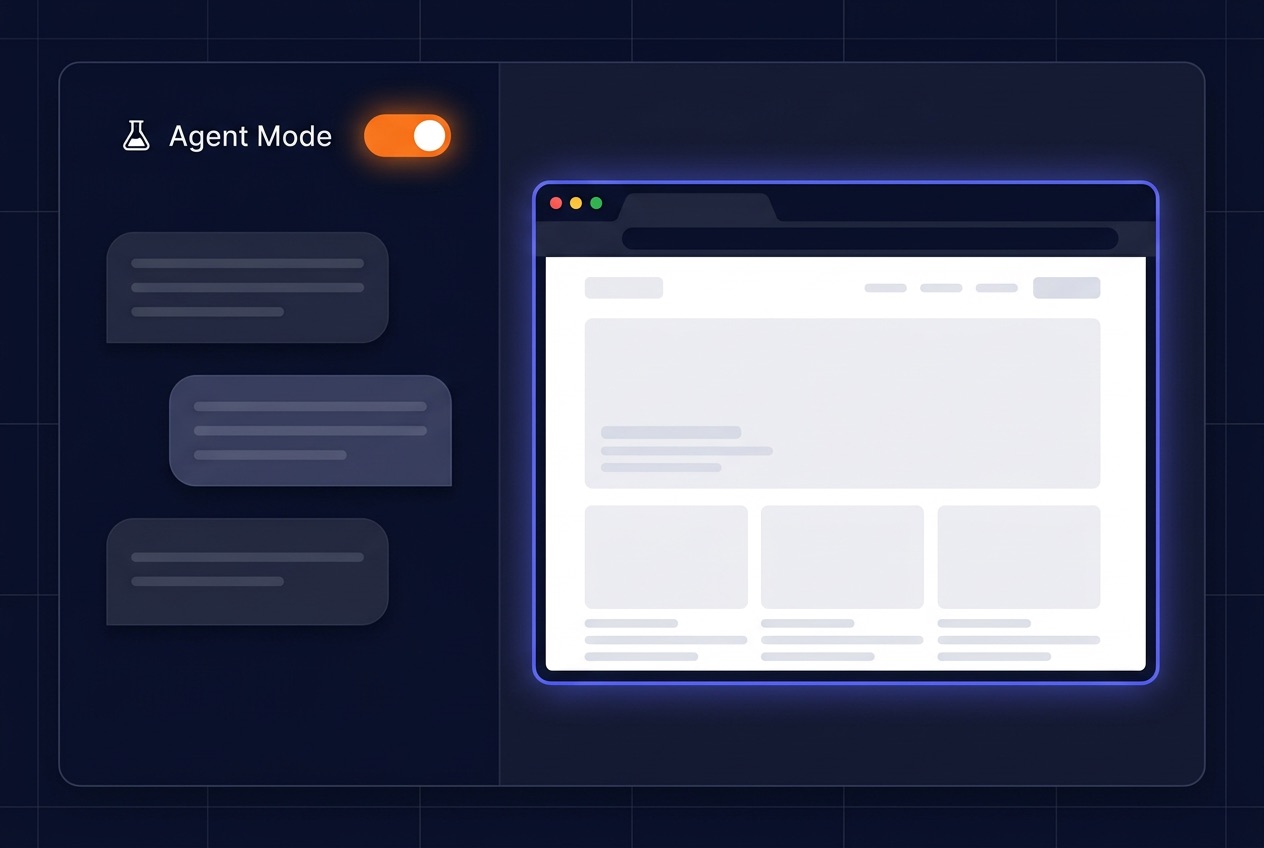
Agent Mode & Enterprise Agents
Un agent IntraGPT est un collègue numérique que vous formez vous-même, équipez d’outils et d’intégrations, puis laissez travailler en autonomie. Pas un simple chatbot, mais un collaborateur avec un intitulé de poste, une expertise, sa propre mémoire et l’accès aux systèmes que vous lui accordez.
- Navigateur Chromium en direct piloté par l’agent
- Word, PDF, Excel et QR codes depuis un seul prompt
- Agents personnalisés par équipe avec leurs propres outils et MCP
Organisations qui nous font confiance
Santé, logistique, finance, retail. Secteurs où confiance et résultats comptent
“IntraGPT nous a fait économiser des dizaines de milliers d'euros en coûts AI externes dès le premier trimestre.”
“Enfin une entreprise néerlandaise qui comprend l'enterprise. Contact personnel et ROI visible en trois mois.”
“Nous payions plus en abonnements AI séparés qu'en IntraGPT. Maintenant contrôle total et un seul interlocuteur.”
Une plateforme. Quatre couches.
L'IA devient une partie intégrante de votre organisation.
La Plateforme IntraGPT
Tout dans une suite contrôlée.
Conseil
L'IA fonctionne avec les personnes et processus.
Développement
Quand le standard ne suffit pas.
Département AI as a Service
Un département AI qui continue à livrer.
Une couche d'intelligence centrale
Base de connaissances interne.
Sécurité enterprise
Infrastructure privée aux Pays-Bas.
Pourquoi la centralisation compte
IntraGPT centralise l'IA.
Sans centralisation
Avec IntraGPT
L'IA devient gérable et contrôlable.
Conçu pour les secteurs réglementés
Confidentialité et conformité obligatoires.
Comment les organisations utilisent IntraGPT
Des résultats concrets dans différents secteurs.
Groupe de santé accélère l'accès aux protocoles
70% de temps de recherche en moins.
70%
Moins de recherche
4 000+
Utilisateurs
Cabinet d'avocats automatise l'analyse contractuelle
60% plus rapide en due diligence.
60%
Due diligence plus rapide
15 000+
Contrats analysés
Chaîne de supermarchés centralise les connaissances
400+ magasins sur une plateforme.
400+
Magasins
80%
Procédures plus rapides
Entreprise logistique automatise les rapports
50% moins de travail manuel.
50%
Moins de travail manuel
2 000
Collaborateurs
Plus qu'une plateforme
L'implémentation est une question d'organisation.
Plus d'expériences. Que des résultats.
L'IA doit faire économiser votre organisation. Une équipe néerlandaise à vos côtés.